Database Scaling Guide: Tips for Full Stack Developers

Table Of Contents
 Stay In-the-loop
Stay In-the-loop
Get fresh tech & marketing insights delivered right to your inbox.
Share this Article



Tags
Category
- .Net Developer
- Adtech
- Android App Development
- API
- App Store
- Artificial Intelligence
- Blockchain Development
- Chatbot Development
- CMS Development
- Cybersecurity
- Data Security
- Dedicated Developers
- Digital Marketing
- Ecommerce Development
- Edtech
- Fintech
- Flutter app development
- Full Stack Development
- Healthcare Tech
- Hybrid App Development
- iOS App Development
- IT Project Management
- JavaScript development
- Laravel Development
- Magento Development
- MEAN Stack Developer
- MERN Stack Developer
- Mobile App
- Mobile App Development
- Nodejs Development
- Progressive Web Application
- python development
- QA and testing
- Quality Engineering
- React Native
- SaaS
- SEO
- Shopify Development
- Software Development
- Software Outsourcing
- Staff Augmentation
- UI/UX Development
- Web analytics tools
- Wordpress Development
Database scaling is a critical facet of application development, demanding strategic prowess from full stack developers. Crafting seamless, high-performance systems necessitates a nuanced understanding of scaling strategies. From horizontal partitioning to sharding, these techniques form the bedrock of database scalability.
This authoritative pursuit ensures optimal resource utilization, catering to the evolving demands of dynamic applications. In this realm, mastery of scaling isn’t just a technical necessity—it’s a testament to a developer’s acumen in architecting resilient, responsive, and future-proof databases.
Why Database Scaling Matters for Full Stack Developer
Optimal Performance and Responsiveness
- Database scaling is crucial for maintaining optimal performance and responsiveness in the face of growing data volumes.
- Prevents sluggish query execution and ensures swift responses to user requests.
Bottleneck Prevention
- Scalability acts as a guard against bottlenecks in the system.
- Guarantees that the database can efficiently handle increased loads, preventing service degradation.
Enhanced User Load Handling
- Fortifies a system’s capability to handle increased user loads and concurrent transactions.
- Critical for sustained growth and a positive user experience.
Scaling Strategies for Efficiency
- Efficient scaling strategies, such as sharding and vertical scaling, empower databases to meet escalating demands.
- Enables databases to scale without compromising operational efficiency.
Risk Mitigation for System Reliability
- Unchecked data growth without corresponding scaling jeopardizes system reliability.
- Hinders real-time decision-making and can negatively impact customer experiences.
Strategic Imperative for Growth
- Embracing proactive database scaling aligns with the ethos of future-proofing.
- Preemptively addresses challenges posed by evolving business landscapes and increasing data complexities.
Technical Optimization and Strategic Imperative
- Prioritizing database scaling is not just a technical optimization but a strategic imperative.
- Essential for enterprises aiming to maintain a competitive edge in the dynamic digital ecosystem.
Proactive Approach for Future-Proofing
- Proactive database scaling addresses challenges posed by evolving business landscapes.
- Ensures the system is prepared for future data complexities and changing demands.
Strategic Hiring for Efficiency
- To ensure efficient database scaling, hiring full-stack developers with expertise in optimization techniques is crucial.
- Developers play a key role in implementing and maintaining effective scaling strategies.
In summary, the importance of database scaling in full-stack development lies in its role in maintaining optimal performance, preventing bottlenecks, handling increased user loads, and strategically positioning enterprises for sustained growth in the dynamic digital landscape.
ALSO READ: GraphQL vs. REST: A Guided Tour for Full Stack Developers
Database Scaling Types Every Full Stack Developer Should Know
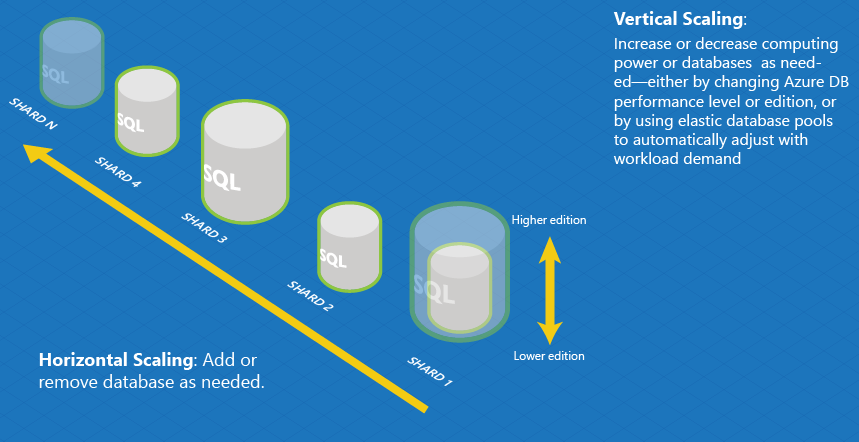
Vertical Scaling (Scaling Up)
It involves increasing the capacity of a single server in a database system to handle more load. It’s achieved by upgrading hardware components like CPU, RAM, or storage.
This scaling type is suitable for applications with varying workloads but has limitations, as it can become expensive and may eventually reach hardware constraints. Unlike horizontal scaling, which adds more servers to distribute the load, vertical scaling focuses on enhancing the capabilities of existing hardware for improved performance.
Horizontal Scaling (Scaling Out)
It involves adding more machines or nodes to a system to handle increased data or traffic. In the context of databases, it means distributing the workload across multiple servers, each capable of independent operation.
This approach enhances performance and accommodates growing demands by dividing the data and queries. Horizontal scaling is often associated with NoSQL databases, enabling seamless expansion by adding servers horizontally rather than vertically upgrading a single server’s capacity.
Hybrid Scaling Approaches
Hybrid scaling approaches combine aspects of vertical and horizontal scaling to optimize performance and flexibility in database systems. This strategy leverages the strengths of both methods, allowing for increased processing power through hardware upgrades (vertical scaling) and enhanced capacity through distributing data across multiple servers (horizontal scaling).
This hybrid approach aims to achieve a balanced and efficient solution for varying database workloads, providing scalability without sacrificing performance or incurring excessive costs.
Database Scaling Strategies for Full Stack Developers
Sharding
This is a pivotal aspect of scaling databases and demands a comprehensive full-stack strategy. At its core, sharding involves horizontally partitioning data across multiple servers, amplifying both storage and processing capabilities. The database schema must be meticulously designed to distribute load efficiently, with careful consideration given to data distribution algorithms.
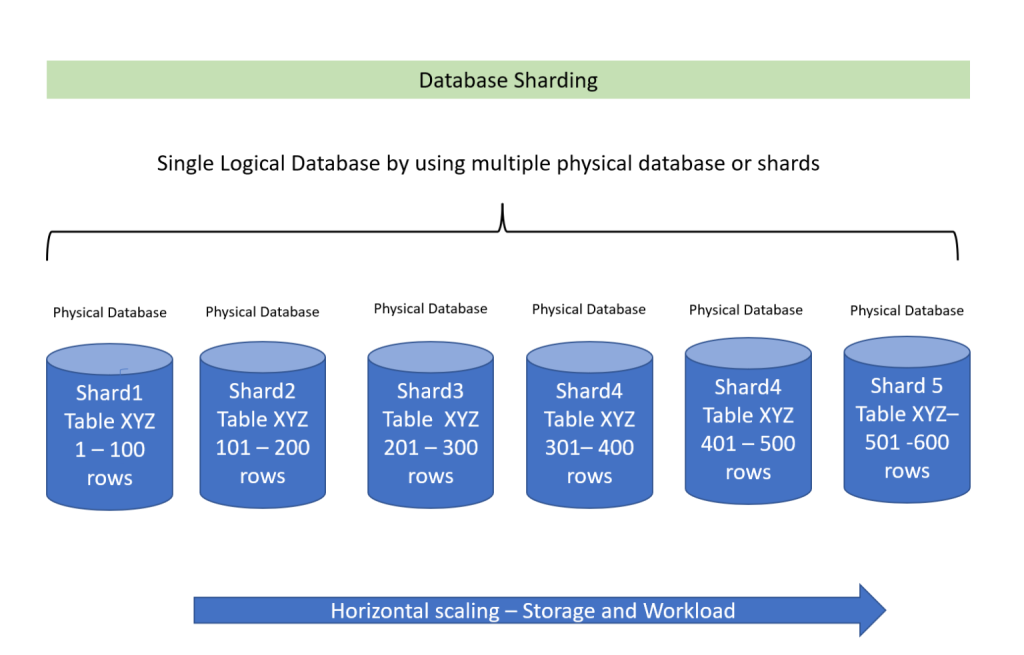
On the server side, an adept load-balancing mechanism is imperative to ensure equitable distribution of queries. Application logic should be intricately woven to recognize and interact seamlessly with sharded data.
Employing a robust indexing strategy becomes paramount for swift retrieval of information. Monitoring tools must vigilantly track shard health, facilitating swift response to potential issues. Consider hiring full-stack software developers adept at sharding for effective database scaling strategies.
A holistic approach to sharding, encompassing database design, server-side optimizations, application logic, and vigilant monitoring, forms the bedrock of an authoritative strategy for scaling databases.
Trust Our Full-Stack Masters for Scalable Database Solutions!
Replication
Replication, a cornerstone in this process, involves duplicating data across multiple servers to enhance performance and ensure fault tolerance. Employing master-slave replication allows read-intensive operations to be distributed among replicas, alleviating the load on the primary server.
Furthermore, sharding, a strategic partitioning technique, enhances horizontal scalability by distributing data across multiple servers based on predefined criteria. This meticulous approach extends beyond database management systems, encompassing efficient query optimization, load balancing, and robust infrastructure.
Seamless integration of these elements ensures a scalable architecture capable of meeting the demands of dynamic, high-traffic applications. While database scaling, the synergy of replication and comprehensive system-level considerations is paramount for achieving optimal performance and reliability.
Caching
Scaling databases necessitates a comprehensive approach to caching across the full stack. Employing an authoritative strategy involves judicious use of caching layers at multiple levels, from database query results to application-level objects. Leverage distributed caching mechanisms to enhance read performance and alleviate database load. Implement intelligent caching strategies, such as content-based or time-based eviction policies, to ensure optimal resource utilization.
Employing in-memory caching technologies like Redis or Memcached enables quick retrieval of frequently accessed data, reducing database latency. Furthermore, adopt a cache-invalidation strategy to maintain data consistency.
A well-orchestrated caching approach, coupled with appropriate tuning at each layer, is imperative for achieving seamless scalability in database systems, ensuring high performance and responsiveness in dynamic, growing environments.
ALSO READ: 6 Reasons Why Node.js is Powering Up SaaS Development
Load Balancing
Effective load balancing is paramount in scaling databases within a full-stack approach. Employing a meticulous strategy ensures optimal resource utilization, preventing bottlenecks and enhancing overall system performance.
On the database tier, horizontal partitioning distributes data across multiple servers, preventing single points of failure. Concurrently, vertical partitioning allocates specific columns to separate databases, streamlining access.
At the application layer, implementing intelligent request routing, utilizing algorithms like Least Connections or Round Robin, optimizes distribution across servers. This strategic approach, combining both database and application-level techniques, fortifies the infrastructure against uneven workloads and facilitates seamless scalability.
Constant monitoring and adaptive load balancing mechanisms further refine the system’s responsiveness, ultimately ensuring a robust, high-performing, and scalable database architecture within the broader full stack ecosystem.
Partitioning
Database partitioning, a crucial scaling technique, involves dividing large datasets into smaller, manageable subsets. Range partitioning organizes data based on predetermined ranges, ideal for chronological data like timestamps.
Hash partitioning distributes data evenly using hash functions, ensuring balanced loads. Benefits include enhanced query performance as operations focus on specific partitions, minimizing resource contention. However, limitations arise with skewed data distribution, impacting load balancing.
Use cases span diverse scenarios, such as eCommerce platforms partitioning customer data for regional load balancing, or timestamp-based partitioning in time-series databases for efficient data retrieval. Although partitioning optimizes performance, careful consideration is needed to address potential challenges, ensuring a well-orchestrated scaling strategy in full-stack development.
Data Consistency and CAP Theorem
CAP Theorem posits that in distributed systems, achieving Consistency, Availability, and Partition Tolerance concurrently is impractical. Consistency ensures all nodes see the same data, Availability guarantees a response for every request, and Partition Tolerance handles network failures.
Scaling databases involves trade-offs. For enhanced consistency, adopt a strong consistency model, sacrificing availability during network partitions. Opting for high availability may lead to eventual consistency, accepting temporary data divergences. Partition tolerance is non-negotiable.
In a full-stack approach, consider sharding for improved scalability, but be mindful of potential consistency issues. Implement eventual consistency through techniques like conflict resolution or causal consistency. Leverage load balancing, caching, and replication strategically to balance trade-offs in a dynamic, scalable database architecture. Optimize database scaling with full-stack developers for hire, balancing data consistency in the CAP Theorem.
ALSO READ: Architecture Patterns in Android App Development: MVC, MVP, MVVM
Database Indexing
Indexing is pivotal in database optimization, enhancing query performance by facilitating rapid data retrieval. Types like B-trees suit range queries, while hash indexes excel with equality queries. Optimal indexing involves strategic selection, balancing speed gains and storage overhead. A composite index on frequently queried columns can further boost efficiency.
Scaling databases demands a holistic approach. Employ sharding to distribute data across multiple servers, alleviating load. Utilize read replicas to enhance read scalability and employ caching mechanisms for frequently accessed data. Regularly analyze query execution plans and fine-tune indexes to adapt to evolving usage patterns.
Thorough indexing and scaling strategies, encompassing both query optimization and system architecture, are indispensable for maintaining high-performance databases in dynamic, full-stack environments.
Auto-scaling in Cloud Environments
Utilizing cloud services like AWS, Azure, and GCP for automatic scaling demands a meticulous approach. Implementing Infrastructure as Code (IaC) ensures swift provisioning, aiding scalability. Leverage AWS Auto Scaling, Azure Autoscale, and GCP’s Managed Instance Groups for dynamic resource allocation.
Consider serverless solutions, such as AWS Lambda or Azure Functions, to optimize costs by paying only for executed functions. Embrace load balancing to distribute traffic efficiently. When scaling databases, opt for managed services like AWS RDS, Azure SQL Database, or GCP Cloud SQL for seamless scalability and automatic backups.
Employ read replicas to enhance database performance without compromising availability. Regularly monitor and fine-tune configurations to align resources with demand, mitigating unnecessary expenses. Prioritize efficient resource utilization and strategic capacity planning for a cost-effective, resilient, and scalable full stack solution.
Need Database Scaling Expertise? Magicminds is Your Go-To Partner!
Contact Us Today!ALSO READ: React Native App Development with AWS Amplify or Firebase
Monitoring and Performance Tuning
For comprehensive database performance monitoring and tuning, adopt a full-stack approach with tools like Prometheus for metric collection, Grafana for visualization, and Percona Toolkit for advanced MySQL performance analysis. Implement query profiling using tools such as pt-query-digest to identify bottlenecks.
Leverage ProxySQL for efficient database connection pooling and load balancing, ensuring optimal resource utilization. Embrace automation with tools like Terraform for scaling infrastructure dynamically. Implementing database sharding strategies with Vitess or CitusDB can enhance horizontal scaling. Regularly conduct database schema reviews and employ Liquibase or Flyway for version-controlled schema management.
Prioritize continuous integration and delivery for seamless updates. Finally, embrace chaos engineering with tools like Chaos Monkey to proactively identify weaknesses in your database infrastructure, fostering a resilient and scalable architecture.
Security Considerations
Scaling databases introduces security challenges like data breaches and unauthorized access. To secure scaled databases, employ encryption for data at rest and in transit. Implement strong access controls, restricting privileges based on roles. Regularly audit and monitor database activities to detect anomalies. Employ database activity monitoring tools for real-time threat detection.
Compliance with regulations like GDPR and HIPAA is crucial. Understand data residency requirements and ensure compliance with regional data protection laws. Conduct regular security assessments and vulnerability scans. Regularly update and patch database systems to mitigate potential exploits. Maintain robust disaster recovery plans to safeguard data integrity.
A full stack developer should stay informed about security best practices across the entire development lifecycle. Be more inclined towards hiring full stack web developers to adhere to secure coding principles, conduct security reviews, and integrate security testing into the CI/CD pipeline. Regularly update dependencies and libraries to address vulnerabilities. Prioritize user privacy and data protection in line with regulatory standards.
ALSO READ: Guide 101: Best Security Tips for Python Developers
Must Know Future Trends in Database Scaling for Full Stack Developers
- The evolving landscape of AI and machine learning development significantly influences the paradigm of database scaling. These technologies reshape how databases operate, optimizing performance and addressing bottlenecks.
- The convergence of full-stack development and intelligent algorithms is going to optimize overall system performance. It mitigates bottlenecks and significantly enhances the scalability of databases.
- The evolving landscape prompts the development of innovative scaling tools that facilitate the integration of intelligent algorithms, further enhancing the efficiency of database scaling.
- Predictive models devised by AI development empower databases to make proactive adjustments based on usage patterns. This proactive approach ensures efficient resource utilization and responsive system behavior.
In short, the future of database scaling is marked by a holistic, AI-driven, and innovative approach, demanding the expertise of skilled professionals to navigate the complexities of dynamic environments.
Why Database Scaling Matters for Full Stack Developer
Optimal Performance and Responsiveness
- Database scaling is crucial for maintaining optimal performance and responsiveness in the face of growing data volumes.
- Prevents sluggish query execution and ensures swift responses to user requests.
Bottleneck Prevention
- Scalability acts as a guard against bottlenecks in the system.
- Guarantees that the database can efficiently handle increased loads, preventing service degradation.
Enhanced User Load Handling
- Fortifies a system’s capability to handle increased user loads and concurrent transactions.
- Critical for sustained growth and a positive user experience.
Scaling Strategies for Efficiency
- Efficient scaling strategies, such as sharding and vertical scaling, empower databases to meet escalating demands.
- Enables databases to scale without compromising operational efficiency.
Risk Mitigation for System Reliability
- Unchecked data growth without corresponding scaling jeopardizes system reliability.
- Hinders real-time decision-making and can negatively impact customer experiences.
Strategic Imperative for Growth
- Embracing proactive database scaling aligns with the ethos of future-proofing.
- Preemptively addresses challenges posed by evolving business landscapes and increasing data complexities.
Technical Optimization and Strategic Imperative
- Prioritizing database scaling is not just a technical optimization but a strategic imperative.
- Essential for enterprises aiming to maintain a competitive edge in the dynamic digital ecosystem.
Proactive Approach for Future-Proofing
- Proactive database scaling addresses challenges posed by evolving business landscapes.
- Ensures the system is prepared for future data complexities and changing demands.
Strategic Hiring for Efficiency
- To ensure efficient database scaling, hiring full-stack developers with expertise in optimization techniques is crucial.
- Developers play a key role in implementing and maintaining effective scaling strategies.
In summary, the importance of database scaling in full-stack development lies in its role in maintaining optimal performance, preventing bottlenecks, handling increased user loads, and strategically positioning enterprises for sustained growth in the dynamic digital landscape.
ALSO READ: GraphQL vs. REST: A Guided Tour for Full Stack Developers
Database Scaling Types Every Full Stack Developer Should Know
Vertical Scaling (Scaling Up)
It involves increasing the capacity of a single server in a database system to handle more load. It’s achieved by upgrading hardware components like CPU, RAM, or storage.
This scaling type is suitable for applications with varying workloads but has limitations, as it can become expensive and may eventually reach hardware constraints. Unlike horizontal scaling, which adds more servers to distribute the load, vertical scaling focuses on enhancing the capabilities of existing hardware for improved performance.
Horizontal Scaling (Scaling Out)
It involves adding more machines or nodes to a system to handle increased data or traffic. In the context of databases, it means distributing the workload across multiple servers, each capable of independent operation.
This approach enhances performance and accommodates growing demands by dividing the data and queries. Horizontal scaling is often associated with NoSQL databases, enabling seamless expansion by adding servers horizontally rather than vertically upgrading a single server’s capacity.
Hybrid Scaling Approaches
Hybrid scaling approaches combine aspects of vertical and horizontal scaling to optimize performance and flexibility in database systems. This strategy leverages the strengths of both methods, allowing for increased processing power through hardware upgrades (vertical scaling) and enhanced capacity through distributing data across multiple servers (horizontal scaling).
This hybrid approach aims to achieve a balanced and efficient solution for varying database workloads, providing scalability without sacrificing performance or incurring excessive costs.
Database Scaling Strategies for Full Stack Developers
Sharding
This is a pivotal aspect of scaling databases, and demands a comprehensive full-stack strategy. At its core, sharding involves horizontally partitioning data across multiple servers, amplifying both storage and processing capabilities. The database schema must be meticulously designed to distribute load efficiently, with careful consideration given to data distribution algorithms.
On the server side, an adept load-balancing mechanism is imperative to ensure equitable distribution of queries. Application logic should be intricately woven to recognize and interact seamlessly with sharded data.
Employing a robust indexing strategy becomes paramount for swift retrieval of information. Monitoring tools must vigilantly track shard health, facilitating swift response to potential issues. Consider hiring full-stack software developers adept at sharding for effective database scaling strategies.
A holistic approach to sharding, encompassing database design, server-side optimizations, application logic, and vigilant monitoring, forms the bedrock of an authoritative strategy for scaling databases.
Replication
Replication, a cornerstone in this process, involves duplicating data across multiple servers to enhance performance and ensure fault tolerance. Employing master-slave replication allows read-intensive operations to be distributed among replicas, alleviating the load on the primary server.
Furthermore, sharding, a strategic partitioning technique, enhances horizontal scalability by distributing data across multiple servers based on predefined criteria. This meticulous approach extends beyond database management systems, encompassing efficient query optimization, load balancing, and robust infrastructure.
Seamless integration of these elements ensures a scalable architecture capable of meeting the demands of dynamic, high-traffic applications. While database scaling, the synergy of replication and comprehensive system-level considerations is paramount for achieving optimal performance and reliability.
Caching
Scaling databases necessitates a comprehensive approach to caching across the full stack. Employing an authoritative strategy involves judicious use of caching layers at multiple levels, from database query results to application-level objects. Leverage distributed caching mechanisms to enhance read performance and alleviate database load. Implement intelligent caching strategies, such as content-based or time-based eviction policies, to ensure optimal resource utilization.
Employing in-memory caching technologies like Redis or Memcached enables quick retrieval of frequently accessed data, reducing database latency. Furthermore, adopt a cache-invalidation strategy to maintain data consistency.
A well-orchestrated caching approach, coupled with appropriate tuning at each layer, is imperative for achieving seamless scalability in database systems, ensuring high performance and responsiveness in dynamic, growing environments.
ALSO READ: 6 Reasons Why Node.js is Powering Up SaaS Development
Load Balancing
Effective load balancing is paramount in scaling databases within a full-stack approach. Employing a meticulous strategy ensures optimal resource utilization, preventing bottlenecks and enhancing overall system performance.
On the database tier, horizontal partitioning distributes data across multiple servers, preventing single points of failure. Concurrently, vertical partitioning allocates specific columns to separate databases, streamlining access.
At the application layer, implementing intelligent request routing, utilizing algorithms like Least Connections or Round Robin, optimizes distribution across servers. This strategic approach, combining both database and application-level techniques, fortifies the infrastructure against uneven workloads and facilitates seamless scalability.
Constant monitoring and adaptive load balancing mechanisms further refine the system’s responsiveness, ultimately ensuring a robust, high-performing, and scalable database architecture within the broader full stack ecosystem.
Partitioning
Database partitioning, a crucial scaling technique, involves dividing large datasets into smaller, manageable subsets. Range partitioning organizes data based on predetermined ranges, ideal for chronological data like timestamps.
Hash partitioning distributes data evenly using hash functions, ensuring balanced loads. Benefits include enhanced query performance as operations focus on specific partitions, minimizing resource contention. However, limitations arise with skewed data distribution, impacting load balancing.
Use cases span diverse scenarios, such as eCommerce platforms partitioning customer data for regional load balancing, or timestamp-based partitioning in time-series databases for efficient data retrieval. Although partitioning optimizes performance, careful consideration is needed to address potential challenges, ensuring a well-orchestrated scaling strategy in full-stack development.
Data Consistency and CAP Theorem
CAP Theorem posits that in distributed systems, achieving Consistency, Availability, and Partition Tolerance concurrently is impractical. Consistency ensures all nodes see the same data, Availability guarantees a response for every request, and Partition Tolerance handles network failures.
Scaling databases involves trade-offs. For enhanced consistency, adopt a strong consistency model, sacrificing availability during network partitions. Opting for high availability may lead to eventual consistency, accepting temporary data divergences. Partition tolerance is non-negotiable.
In a full-stack approach, consider sharding for improved scalability, but be mindful of potential consistency issues. Implement eventual consistency through techniques like conflict resolution or causal consistency. Leverage load balancing, caching, and replication strategically to balance trade-offs in a dynamic, scalable database architecture. Optimize database scaling with full stack developers for hire, balancing data consistency in CAP Theorem.
ALSO READ: Architecture Patterns in Android App Development: MVC, MVP, MVVM
Database Indexing
Indexing is pivotal in database optimization, enhancing query performance by facilitating rapid data retrieval. Types like B-trees suit range queries, while hash indexes excel with equality queries. Optimal indexing involves strategic selection, balancing speed gains and storage overhead. A composite index on frequently queried columns can further boost efficiency.
Scaling databases demands a holistic approach. Employ sharding to distribute data across multiple servers, alleviating load. Utilize read replicas to enhance read scalability and employ caching mechanisms for frequently accessed data. Regularly analyze query execution plans and fine-tune indexes to adapt to evolving usage patterns.
Thorough indexing and scaling strategies, encompassing both query optimization and system architecture, are indispensable for maintaining high-performance databases in dynamic, full-stack environments.
Auto-scaling in Cloud Environments
Utilizing cloud services like AWS, Azure, and GCP for automatic scaling demands a meticulous approach. Implementing Infrastructure as Code (IaC) ensures swift provisioning, aiding scalability. Leverage AWS Auto Scaling, Azure Autoscale, and GCP’s Managed Instance Groups for dynamic resource allocation.
Consider serverless solutions, such as AWS Lambda or Azure Functions, to optimize costs by paying only for executed functions. Embrace load balancing to distribute traffic efficiently. When scaling databases, opt for managed services like AWS RDS, Azure SQL Database, or GCP Cloud SQL for seamless scalability and automatic backups.
Employ read replicas to enhance database performance without compromising availability. Regularly monitor and fine-tune configurations to align resources with demand, mitigating unnecessary expenses. Prioritize efficient resource utilization and strategic capacity planning for a cost-effective, resilient, and scalable full stack solution.
ALSO READ: React Native App Development with AWS Amplify or Firebase
Monitoring and Performance Tuning
For comprehensive database performance monitoring and tuning, adopt a full-stack approach with tools like Prometheus for metric collection, Grafana for visualization, and Percona Toolkit for advanced MySQL performance analysis. Implement query profiling using tools such as pt-query-digest to identify bottlenecks.
Leverage ProxySQL for efficient database connection pooling and load balancing, ensuring optimal resource utilization. Embrace automation with tools like Terraform for scaling infrastructure dynamically. Implementing database sharding strategies with Vitess or CitusDB can enhance horizontal scaling. Regularly conduct database schema reviews and employ Liquibase or Flyway for version-controlled schema management.
Prioritize continuous integration and delivery for seamless updates. Finally, embrace chaos engineering with tools like Chaos Monkey to proactively identify weaknesses in your database infrastructure, fostering a resilient and scalable architecture.
Security Considerations
Scaling databases introduces security challenges like data breaches and unauthorized access. To secure scaled databases, employ encryption for data at rest and in transit. Implement strong access controls, restricting privileges based on roles. Regularly audit and monitor database activities to detect anomalies. Employ database activity monitoring tools for real-time threat detection.
Compliance with regulations like GDPR and HIPAA is crucial. Understand data residency requirements and ensure compliance with regional data protection laws. Conduct regular security assessments and vulnerability scans. Regularly update and patch database systems to mitigate potential exploits. Maintain robust disaster recovery plans to safeguard data integrity.
A full stack developer should stay informed about security best practices across the entire development lifecycle. Be more inclined towards hiring full stack web developers to adhere to secure coding principles, conduct security reviews, and integrate security testing into the CI/CD pipeline. Regularly update dependencies and libraries to address vulnerabilities. Prioritize user privacy and data protection in line with regulatory standards.
ALSO READ: Guide 101: Best Security Tips for Python Developers
Must Know Future Trends in Database Scaling for Full Stack Developers
- The evolving landscape of AI and machine learning development significantly influences the paradigm of database scaling. These technologies reshape how databases operate, optimizing performance and addressing bottlenecks.
- The convergence of full-stack development and intelligent algorithms is going to optimize overall system performance. It mitigates bottlenecks and significantly enhances the scalability of databases.
- The evolving landscape prompts the development of innovative scaling tools that facilitate the integration of intelligent algorithms, further enhancing the efficiency of database scaling.
- Predictive models devised by AI development empower databases to make proactive adjustments based on usage patterns. This proactive approach ensures efficient resource utilization and responsive system behavior.
In short, the future of database scaling is marked by a holistic, AI-driven, and innovative approach, demanding the expertise of skilled professionals to navigate the complexities of dynamic environments.
